为何响应时间常被测错
响应时间在许多情况下都是性能分析的基础。它们处于预期的界限内时,一切正常;而一旦过高,我们就得开始优化应用。
因此响应时间在性能监测和分析中扮演着核心角色。在虚拟化和云环境中,它们也是您能得到的最准确的性能指标。但很多情况下,人们却以错误的方式测量并解释响应时间。为此我们有充足的理由来讨论响应时间测量以及如何对其进行解释这一话题。下面我将讨论典型测量手段、相关的误解以及如何改善测量手段等问题。
信息被平均丢了
在测量响应时间时,我们无法逐个查看测量结果。即便是在非常小的生产系统中,事务数量也多到难以应付。因此测量结果都要在某一时间框架内汇总到一起。按照应用配置的不同,这可能是几秒、几分甚至几小时。
尽管这种汇总帮助我们轻松理解大型系统中的响应时间,但也意味着我们丢失了信息。最常见的测量汇总方法是采用平均值。这就是说所采集到的测量结果被平均到一起,这样我们处理的就是平均值,而非真实值。 平均值的问题在于它们在很多情况下并没有反映真实世界中发生的情况。使用平均值时,之所以会引起错误或者误导性结果,主要原因共有两个。
如果测量结果取值波动较大,那么平均值无法代表实际测量的响应时间。如测量结果的范围介于1 到 4 秒之间,那么平均值可能是在 2 秒左右,这当然并不代表很多用户的感受。 因此平均值仅对真实世界的性能提供了很少的帮助。所以不应该只使用平均值,而应使用百分位数。如果您与那些在性能领域工作过一段时间的人们交流,他们会告诉你用起来可靠的唯一指标就是百分位数。与平均值相反,百分位数定义了有多少用户体会到的响应时间低于某一门限值。举例来说,如果第 50 百分位数为 2.5 秒,则意味着对于百分之 50 的用户,响应时间都小于或者等于 2.5 秒。可以看出,这种手段与平均值相比更接近于现实。
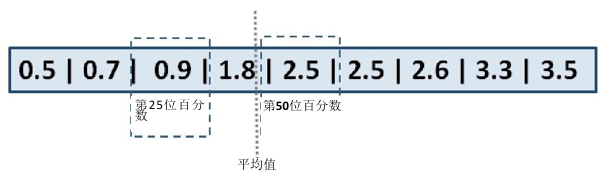
测量结果序列的百分位数和平均值
百分位数唯一的潜在缺陷是它们要求的数据存储量要高于平均值。平均值计算仅要求所有测量结果的总和以及数量,而百分位数的计算却更为复杂,它要求整个范围内的测量结果取值。正是由于这个原因,并不是所有性能管理工具都支持百分位数。
所有东西都被混到一起
数据汇总中另一个重要问题是就是采用哪些数据作为汇总依据。如果把不同事务类型的数据混合到一起,比如起始页、查找和信用卡确认,那么结果就鲜有价值,原因就在于基础数据的差别就像苹果和桔子一样。因此除了确保使用百分位数外,还有必要正确拆分事务类型,以使计算所依据的数据能够匹配到一起。
按照业务功能来拆分事务的概念通常被称为自定义事务。虽然自定义事务基本理念就是通过一些请求参数来区分应用中的事务,这些参数例如这些事务是干什么的或者来自哪里,或者按照逻辑关系让用户有选择的对事务进行聚合等。比如说“放入购物篮”事务或者某一用户的请求等。